数学家使用马尔可夫链帮助提高数据中心的效率
RUDN大学的数学家创建了一个最大的数据中心效率模型。它基于非平凡的马尔可夫链。除了将结果用于服务器和数据中心的组织的明显实际应用之外,理论部分还将对队列和排队论以及大数据和神经网络的工作很有用。这项研究发表在“数学”杂志上。
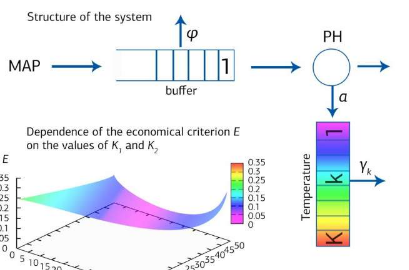
数据中心是一个服务器系统,其任务是根据用户的要求提供计算资源和磁盘空间。负载越高,设备发热量就越大。如果服务器过热,则服务器可能会暂时停止工作。对应于过热点的温度水平称为第一临界水平。第二个是服务器温度必须下降到一定水平才能恢复(至少部分)工作。
这些级别是不同的。例如,如果每个用户加载服务器,以使其处理器的温度升高0.1度,并且第一临界级别为100度,则第二临界级别应设置为不高于99.9度。如果放在上面,则用户的第一个请求将再次使服务器过热。在这种情况下,两个关键级别应放置得足够近,如果它们之间的差异很大,则服务器容量将无法完全使用。必须配置这些级别,以使数据中心的服务器不会由于过热而持续关闭,并且同时在满负荷的情况下工作。
RUDN大学的数学家Olga Dudina和Alexander Dudin能够找到优化问题的解决方案,从而确保服务器以最大容量工作,但不会过热。其条件如下所示:根据模拟用户流的随机过程,放置两个关键级别以防止过热,但是将最大程度地利用计算能力。同时,允许部分不活动,即,如果超过第二临界温度水平,则拒绝来自用户的某些请求。
数学家们针对临界值的不同值求解了概率方程。作为模拟用户到达的随机过程,RUDN大学的数学家使用了马尔可夫链。这种链的最简单的例子是沿直线的点的随机游动。每秒都会扔出一枚硬币:如果抬起头,则该点向前移动1厘米;然后,向上移动1厘米。如果有尾巴,则向后1厘米。在此过程中时间是离散的,也就是说,变化每秒发生一次,而将来点的位置仅取决于其当前位置和抛硬币的结果。
为了测试其方法的有效性,RUDN大学的数学家进行了数值实验,以模拟服务器的行为。其结果使用指标E进行评估,指标E是一种质量标准,可以确定用户拒绝服务和每单位时间设备过热所造成的损失。事实证明,新方法允许从0.31到0.03的十倍以上的时间来减少模拟服务器的损失并显着提高数据中心的效率。
同样,起源于数学家的马尔可夫链具有一些有趣的特性。除了在IT中的应用外,它们的模型在排队论中也将是有用的。该理论对于解决排队问题,使用大数据和神经网络非常必要。